
研究 > 情報検索
情報検索
(自動分類、クラスタリング、文書の構造化、質問応答、セマンティックWeb、デジタル図書館など)
WWWをはじめ、世の中には多くのデジタル文書が存在し、必要な情報を容易に参照できる環境の提供が望まれている。このような状況を鑑み、分類、変換、要約、換言などの文書加工技術、また、情報検索、情報抽出などの文書アクセス技術の開発を進めている、また、名古屋大学で生産された学術論文やWebサイトなどの文書データを用いた実証実験をブラッシュアップを図っている。これらの技術を統合することにより、デジタル図書館機能を備えた大学の学術情報基盤のモデル形成、ならびに、大学の知的生産物を社会へ還元する情報発信機能の構築を目指している。
ハイパーリンクを用いたWebディレクトリの自動構築
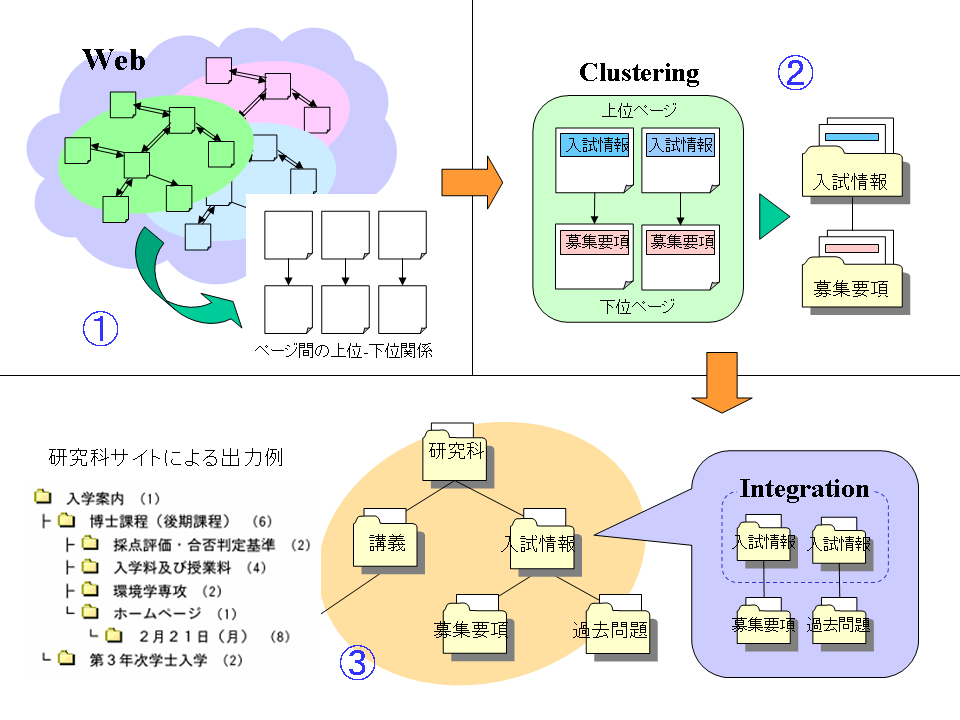
Web上から必要な情報を効率よく得るために,Webページがあらかじめ効果的に整理されていることが望まれる.そこで,本研究では,共通した分野のWebページをその分野に適した階層構造で整理したWebディレクトリを自動で構築することを目的としている.
本手法では,Webディレクトリの階層構造を作成するために,Webページ間のハイパーリンクをもとにページ間の意味的な上位-下位関係を抽出する(①).抽出した上位-下位関係は内容でクラスタリングしてディレクトリにまとめ(②),さらに,内容が類似したディレクトリを統合してディレクリ構造を階層化することにより,Webディレクトリを作成する(③).
学術文書流通とデジタルライブラリへの応用 - plum
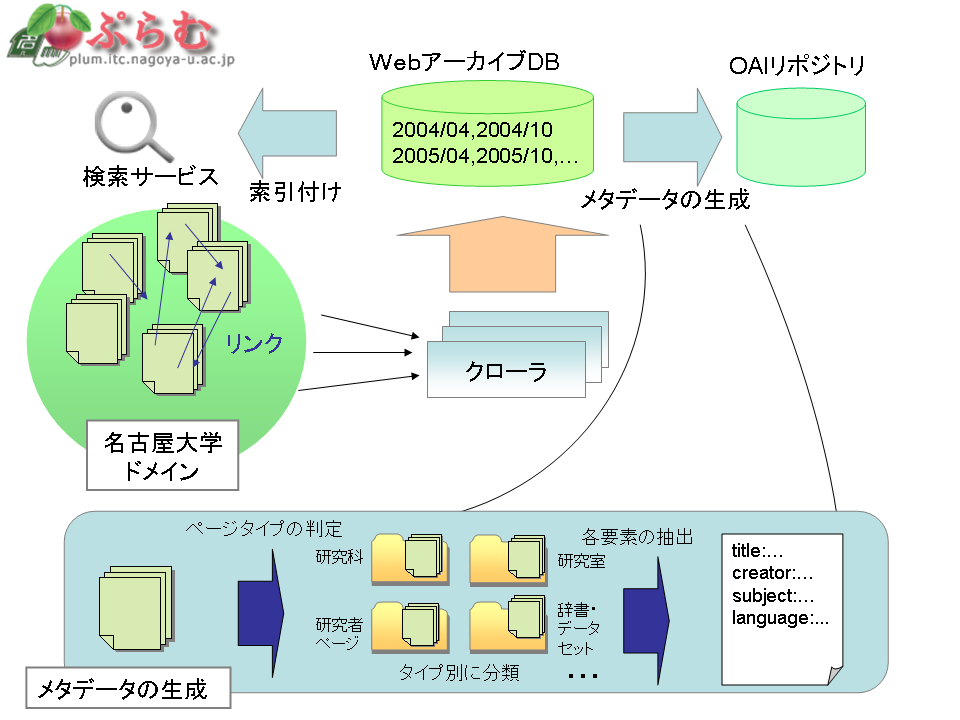
学内の全Webサイトから定期的にWebページを収集し,学内の学術流通情報基盤の整理を行っている. 以下に実際行っているプロジェクトをリストで示す.
- 名古屋大学の全Webサイトからクローラを用いて定期的にデータ収集し,アーカイビングをする.
- 最新のアーカイブデータにインデックスを作成することで,名古屋大学の検索サービスを提供する.
- また,アーカイブデータをカテゴリ別に分類することでカテゴリ検索を可能としている.
- アーカイブデータにメタデータを自動的に付与し,OAI-PMHに対応した検索を可能にする.
- メタデータの生成は,ページタイプを判定し,それから,ページ内の構造,リンク情報などを用いることで自動的に行う.
自然言語を用いたXML文書の検索
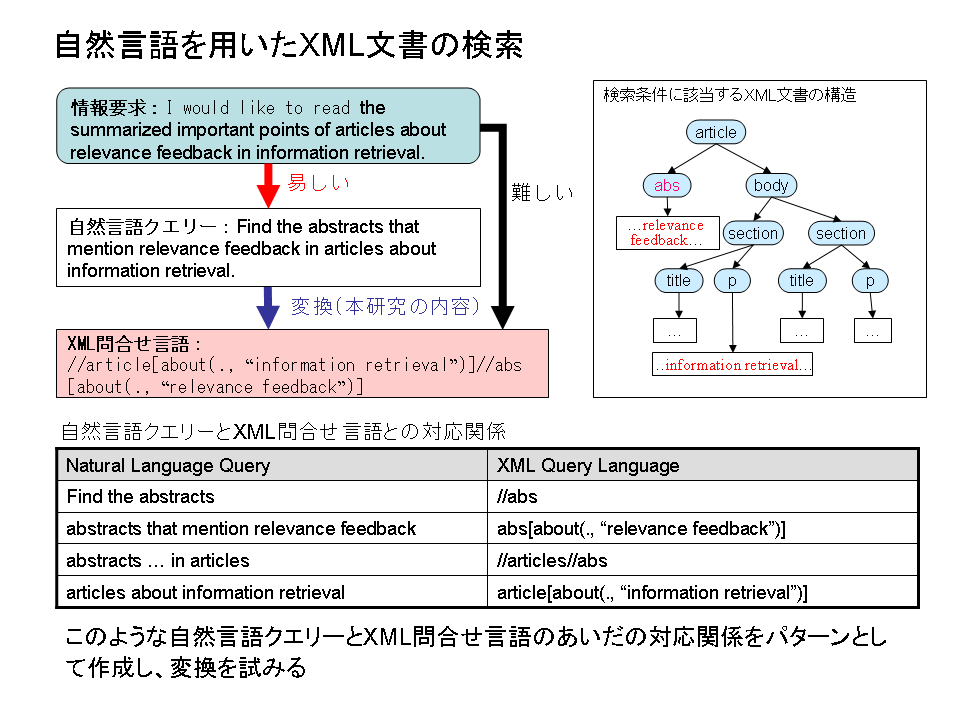
XML文書を対象とした情報検索では,利用者はその文書構造を利用した検索を行ったり,出力結果として文書構造の一部を指定したりできる.通常,このような選択条件や出力文書構造を指定した検索を行うには,XML問合せ言語を用いる.しかし問合せ言語は構文が複雑であったり,文書構造についての知識が必要であったりするので,一般利用者が利用するには不向きである.これに対し,自然言語で情報要求を記述することは容易である.
以上より,XML文書を対象とした情報検索の入力として,自然言語を用いることは有用であると考えられる。本研究では,自然言語によるXML文書の検索を実現するために,自然言語からXML問合せ言語への変換を行うことを考える.自然言語クエリー中の,利用者の内容的および構造的な情報要求を,パターンとマッチングさせることによって抽出し,XML問合せ言語へと変換する.