
研究 > 言語情報処理
研究 ― 言語情報処理
(言語論、言語理解・生成、自動要約、対訳辞書の生成、マイニングなど)
解説:
ロバストで使いやすい自然言語システムの要素技術として、言語処理の高速化に関する研究を進めている。その一手法として、全身的な言語解析アルゴリズムを考案し、また、確率文脈、自由文法、木接合文法、依存文法、有限状態オートマトンなどを用いて実装し、高速化への高い効果を実証している。この技術は同時通訳木などの高度アプリケーションの設計・開発にも応用されている。同時通訳は人間にとって極めて高度な言語行為であり、その仕組みを解明するための言語分析にも取り組んでいる。
大規模構文木コーパスを用いた漸進的構文解析

漸進的構文解析とは,自然言語文の構文構造をその単語の出現順序に沿って段階的に生成する手法である.同時通訳システムのようなリアルタイム言語処理システムに必要な要素技術の一つである.また,漸進的構文解析は,認知科学の分野で人間の言語理解過程をモデル化するためにも利用されており,その応用範囲は工学の分野にとどまらない.我々の研究室では,高精度で頑健な漸進的構文解析の実現を目的に,構文木コーパスに基づく漸進的構文解析手法を開発している.構文木コーパスから構文構造の用例を大量に収集し,それらを逐次的に組み合わせて構文構造を段階的に生成する漸進的構文解析手法を開発している.
オープンソースソフトウェアマニュアル文からの対訳パターン自動抽出
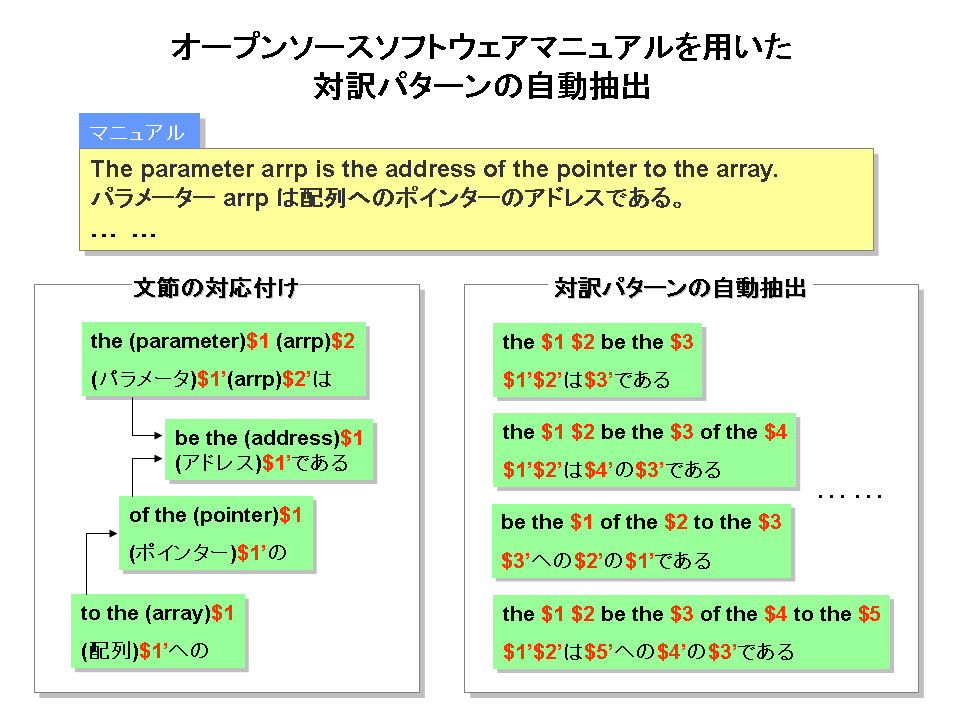
LinuxやFreeBSDなどのオープンソースソフトウェアでは,通常,オンラインマニュアルが用意されているが,その多くは英語版が配布されている.その日本語化がボランティアで行われているものの,マニュアルの翻訳と管理に関するコストは小さくない.そこで本稿では,オープンソースソフトウェアマニュアル文書翻訳で利用可能な対訳パターンの自動抽出手法について述べる.本研究では,対象とするソフトウェアとしてRedHatLinux9.0を使用する.すでに配布されている英語マニュアル文,及び,その日本語訳文を対訳コーパスとして整備し,そこから対訳パターンを獲得する.本手法では,まず,日本語文に出現する分野特有の英文字列を手がかりに対訳文対応付けを行い,対訳辞書を用いて対訳語を抽出する.次に,両言語文の依存解析により,依存構造を構成する部分木間の対応として,対訳パターンを取り出す.対訳パターン抽出実験により,本手法の利用可能性を確認した.
判決文に対する自動要約生成
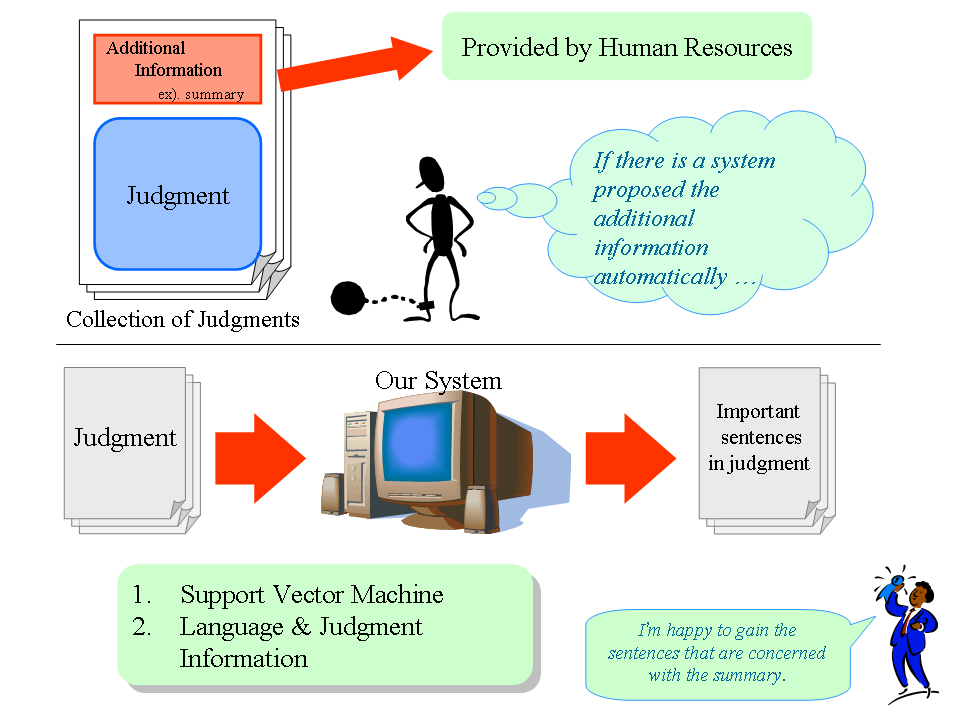
判決文には検索支援のために要旨などの付加情報が与えられている.これらは人手で作成されており,その負担は大きい.システムによってその候補を提示することで負担の軽減が可能となる.要旨は,判決文の“理由”から作成されるため,理由から重要文を抽出することで要約を行う.最高裁判所の判決文から構築した判例コーパスから判決文の特徴を取り出し,機械学習手法の一つであるSVMを用いて学習することで重要文抽出を行う.SVMで使用する特徴として,言語情報と判決文オリジナルな情報を使用した.判決文には必ず要旨が与えられるため,SVMの結果を用いてシステムとしての出力を決定する.